
Graficando con Python
Entre las librerías mas populares de Python tenemos a:
Matplotlib
Nos permite gráficar desde histogramas hasta gráficas lineales y mapas de calor. Tiene un soporte completo a gráficas 2D y un soporte limitado a gráficas 3D.
Seaborn
Esta librería nos permite crear gráficas estadisticas atractivas e informativas. Esta basado en matplotlib. Su objetivo es hacer de las visualizaciones un parte central de la exploracion de datos y nos permite crear visualizaciones mas complejas.
Lo primero que tenemos que hacer es importar alguna de las librerías:

El primer tipo de gráfica que veremos sera:
Gráficas Lineales
Generalmente se usa para presentar observaciones recolectadas en intervalos regulares. En el eje x se representa el intérvalo regular, como el tiempo. En el eje y mostramos las observaciones, ordenadas por el eje x y conectadas por una linea.
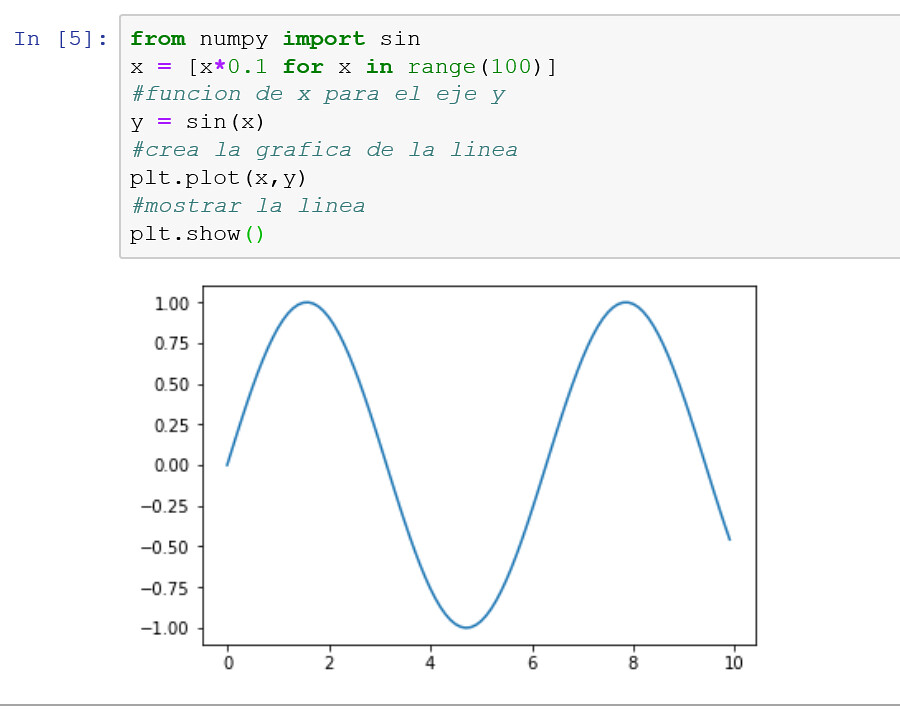
Esta línea se crea llamando a la funcion plot() que recibe dos parametros: Los datos para el eje x que contiene los intervalos regulares y las observaciones para el eje y. Este tipo de graficos son bastante utiles para presentar series de tiempo y secuencias de datos donde hay una orden entre las observaciones.
Al ejecutar el ejemplo se crea un diagrama de líneas que muestra el patrón de onda sinusoidal en el eje y a lo largo del eje x con un intervalo constante entre las observaciones.
El mismo ejemplo se ve de este modo usando Seaborn. Es importante recalcar que no se omite la libreria de matplotlib.
Bar Chart
Este gráfico generalmente se usa para presentar cantidades relativas para categorias multiples.
El eje x representa las categorías y están espaciadas uniformemente. El eje y representa la cantidad para cada categoría y se dibuja como una barra desde la línea de base hasta el nivel apropiado en el eje y.
Se puede crear un gráfico de barras llamando a la función bar() y pasando los nombres de las categorías para el eje x y las cantidades para el eje y.
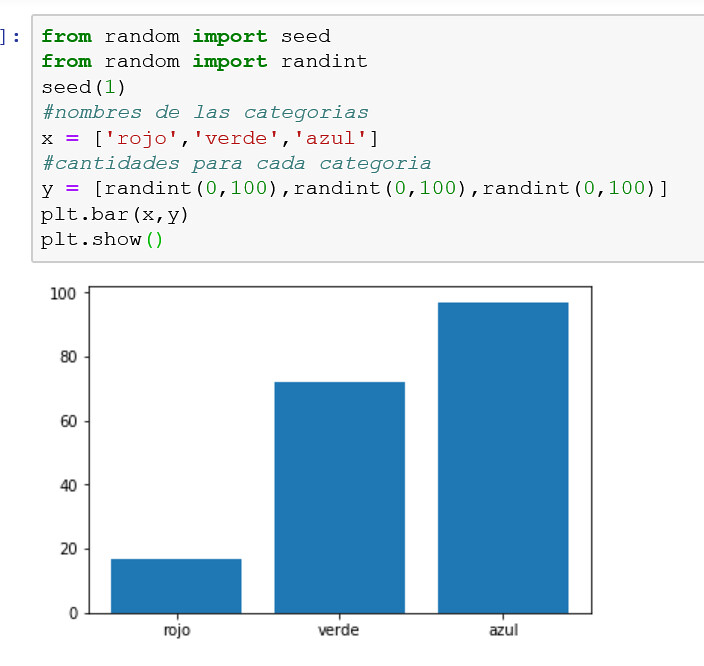
Un gráfico de barras puede ser util para comparar multiples cantidades de puntos o estimaciones.
En el ejemplo anterior se crea un set de datos con tres categorias, cada una definida con una etiqueta. Se dibuja un único valor entero aleatorio para la cantidad en cada categoría.
En Seaborn este ejemplo se ve de este modo, en este caso no usamos matplotlib, solamente los metodos propios de Seaborn.
Histogramas
Un histograma generalmente se use para resumir la distribucion de una muestra de datos.
El eje x representa intérvalos discretos o intervalos para las observaciones. Por ejemplo, las observaciones con valores entre 1 y 10 se pueden dividir en cinco barras, los valores [1,2] se asignarán a la primera barra, [3,4] se asignarán a la segunda barra, y así sucesivamente.
El eje y representá la frecuencia o el recuento del número de observaciones en el conjunto de datos que pertenecen a cada barra.
Esencialmente, una muestra de datos se transforma en un gráfico de barras donde cada categoría en el eje x representa un intervalo de valores de observación.
Se puede crear un diagrama de histograma llamando a la función hist() y pasando una lista o matriz que representa la muestra de datos.
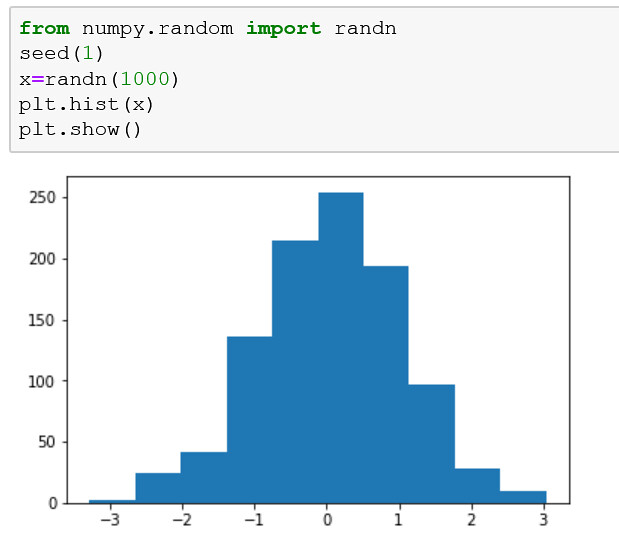
Siguiendo el ejemplo, podemos ver que la forma de las barras muestra la curva en forma de campana de la distribución gaussiana. Podemos ver que la función eligió automáticamente el número de barras, en este caso dividiendo los valores en grupos por valor entero.
En Seaborn este ejemplo con un histograma se ve de este modo, en este caso no usamos matplotlib, solamente los metodos propios de Seaborn.
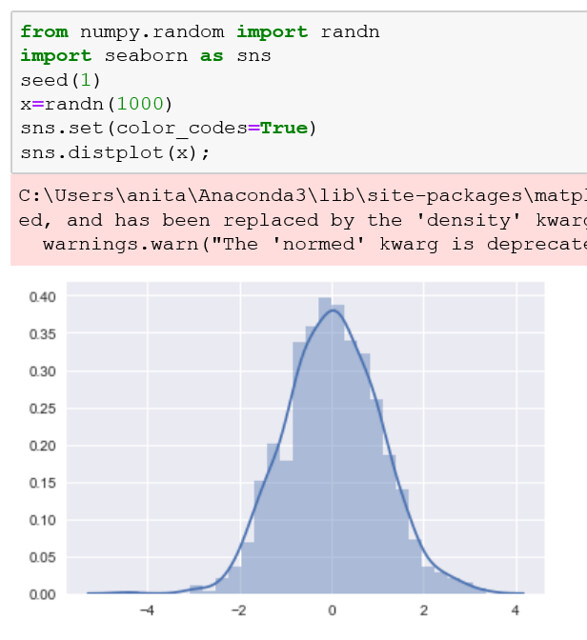
Diagrama de caja (Diagrama de caja y bigotes)
Una gráfica de caja y bigotes generalmente se usa para resumir la distribución de una muestra de datos siendo una alternativa a los histogramas.
El eje x se utiliza para representar la muestra de datos, donde se pueden dibujar varios diagramas de caja uno al lado del otro si se desea.
El eje y representa los valores de observación. Se dibuja un cuadro para resumir el 50% medio del conjunto de datos que comienza en la observación en el percentil 25 y termina en el percentil 75. La mediana, o percentil 50, se dibuja con una línea. Un valor llamado rango intercuartil, o IQR, se calcula como 1.5 * la diferencia entre los percentiles 75 y 25. Las líneas llamadas bigotes se dibujan extendiéndose desde ambos extremos de la caja con la longitud del IQR para demostrar el rango esperado de valores sensibles en la distribución. Las observaciones fuera de los bigotes pueden ser valores atípicos y se dibujan con pequeños círculos.
Los diagramas de caja se pueden dibujar llamando a la función boxplot() que recibe la muestra de datos como una matriz o lista.
Estos diagramas pueden ayudar a obtener rápidamente una idea del rango de valores comunes y sensibles en la caja y en el bigote, respectivamente. Debido a que no estamos observando la forma de la distribución explícitamente, este método se usa a menudo cuando los datos tienen una distribución desconocida o inusual, como la no gaussiana.
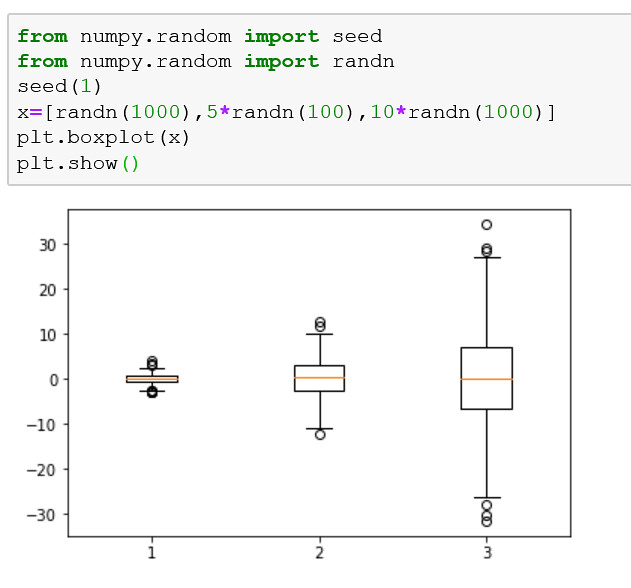
El ejemplo crea tres diagramas gráfico, cada uno de los cuales resume una muestra de datos extraída de una distribución gaussiana ligeramente diferente. Cada muestra de datos se crea como una matriz y las tres matrices de muestras de datos se agregan a una lista que se rellena a la función de trazado.
En Seaborn este ejemplo con un histograma se ve de este modo, en este caso no usamos matplotlib, solamente los metodos propios de Seaborn.
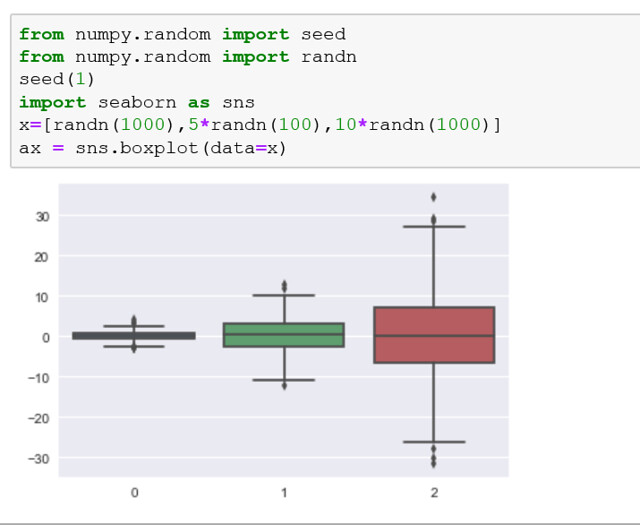
Grafico de Dispersion
Un gráfico de dispersión se utiliza generalmente para resumir la relación entre dos muestras de datos emparejados.
Las muestras de datos emparejados significan que se registraron dos medidas para una observación dada, como el peso y la altura de una persona.
El eje x representa los valores de observación para la primera muestra, y el eje y representa los valores de observación para la segunda muestra. Cada punto en la trama representa una sola observación.
Se puede cuantificar una correlación, como una línea de mejor ajuste, que también se puede dibujar como un trazado de líneas en el mismo gráfico, lo que hace que la relación sea más clara.
Un conjunto de datos puede tener más de dos medidas (variables o columnas) para una observación determinada. Una matriz de gráfico de dispersión es un carro que contiene gráficos de dispersión para cada par de variables en un conjunto de datos con más de dos variables.
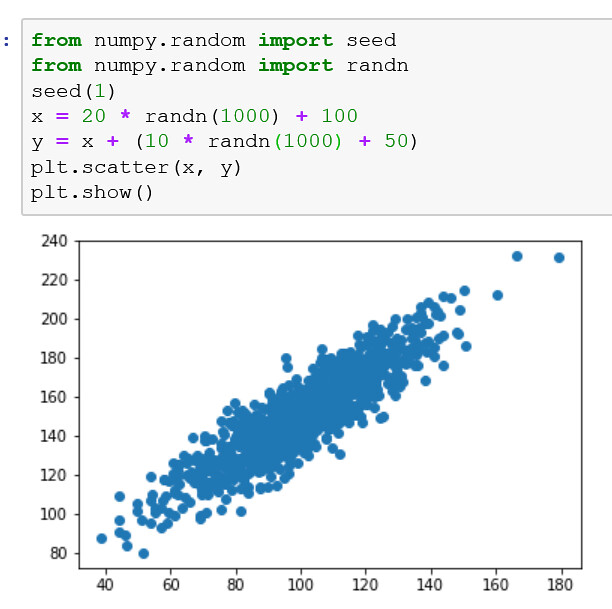
El ejemplo crea dos muestras de datos que están relacionadas. La primera es una muestra de números aleatorios extraídos de un gaussiano estándar. El segundo depende del primero al agregar un segundo valor gaussiano aleatorio al valor del primer compás.
En Seaborn este ejemplo con un grafico de dispersion se ve de este modo, en este caso no usamos matplotlib, solamente los metodos propios de Seaborn.
Recursos Adicionales
Este post encontraras un ejemplo completo de visualizacion con matplotlib. Te animas a crear tu propia version usando Seaborn?
Si te interesa explorar otros lenguajes de programacion, este sitio de la BBC te muestra como realizan sus visualizaciones usando R.
Last updated
Was this helpful?